Supervised learning is great. You provide data and labels and the model will be trained. The state of the art in computer vision is almost solely based on supervised learning. But there’s a cost that’s associated with labeling of data that usually simplified in terms of time and monetary resources an organization has to put so as to get the whole or a significant portion of their raw dataset labeled. In this post, we are going to take a look at active learning and how it can mitigate the challenges of supervised learning. I am going to introduce various components required in order to train a model using active learning. My sole purpose in this post is to demonstrate the steps involved in active learning using a simple structured dataset. In my next post, we will build upon it and train a classifier for computer vision applications.
Active Learning
Active learning is a machine learning technique in which the models can interactively query a user (usually referred to as an oracle) to label new data points. To be clear, active learning does in fact require labeled data. The difference between active learning and supervised learning is that the data requirements comparatively tends to be a fraction of the latter. Active learning falls in the category of semi-supervised learning.
Please refer to my kaggle notebook for the complete code.
Dataset
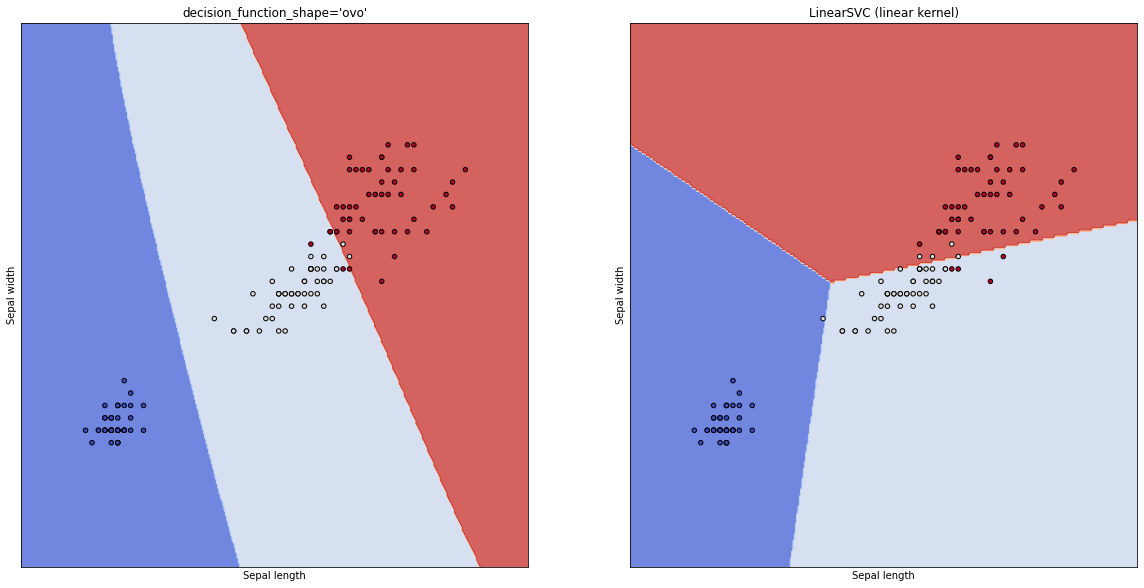
We are going to use the Iris dataset which has 3 values as the target variable that depends on 4 independent variables. Now, for the sake of easy visualization, I am only going to use 2 variables to train SVM classifiers. We are going to train on two different types of SVM kernels.
f1, f2, target = 'petal_length','petal_width', 'species'
X = df[[f1,f2]].reset_index(drop=True)
Y = df[target].reset_index(drop=True)
Supervised learning
Let’s train dirty classifiers for baseline.
from sklearn import svm
clf_ovo = svm.SVC(decision_function_shape='ovo')
clf_Linear = svm.LinearSVC(C=1.0, max_iter=10000)
models = [clf_ovo, clf_Linear]
models = [clf.fit(X, Y) for clf in models]
The fitting of the models is shown below.
Active learning
Break out a small part of the dataset as the pool. We will be training on the pool which is a much smaller subset of the main dataset.
from sklearn.model_selection import train_test_split
X_pool, X_test, y_pool, y_test = train_test_split(X, Y, test_size=0.6, random_state=6)
The Oracle
The job of the oracle is to label the data points that the model is most uncertain on. Since we are using SVM classifiers, we can use sklearn’s decision_function in order to get uncertainty on data points.
def getdatapoint4activelearning(clf,pts):
idxs = []
for clf in clfs:
decisions = (np.abs(list(clf.decision_function((X_pool.reset_index(drop=True))[min(pts):max(pts)]))))
idx = np.argmin(np.array(decisions),axis=0)
idxs.append(idx)
return idxs
Now we are going to repeat the following steps:
- Train SVMs on the subset of random points from the pool.
- Find the most uncertain points from the remaining points in the pool.
- Add it to training sample (optional: you can add a few more data points along with the uncertain points)
- Repeat
import random
begining_thesh = 5 #initial observation
idxs = list(random.sample(range(0, len(X_pool)), begining_thesh))
ambigious_pts = None
clfs_combo = models()
for i in range(10):
clfs = clfs_combo.fit(X_pool,y_pool,idxs)
unknown_idxs = [i for i in range(len(X_pool)) if i not in idxs]
idxs = plot_svm_amb(idxs, models=clfs,ambigious=ambigious_pts)
ambigious_pts = getdatapoint4activelearning(clfs,unknown_idxs)
As you can below, the data points denoted as a star are the points that the model is most uncertain about. As we add these points, the latest model generalizes better than previous models.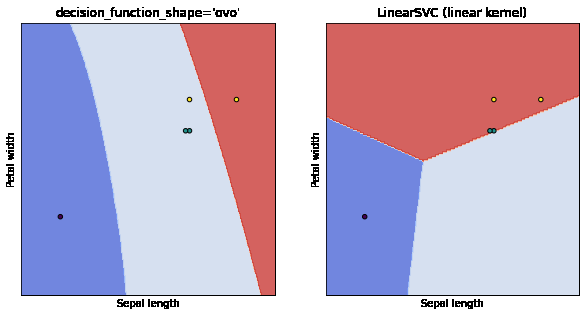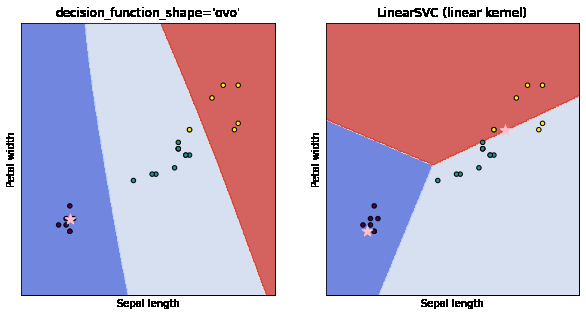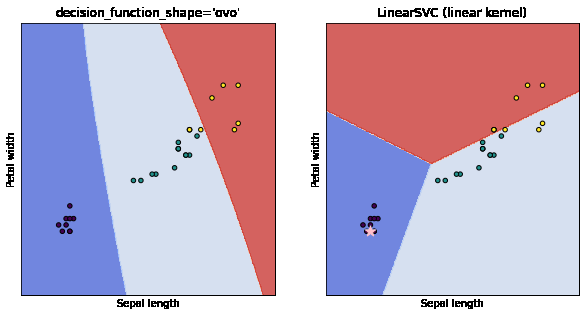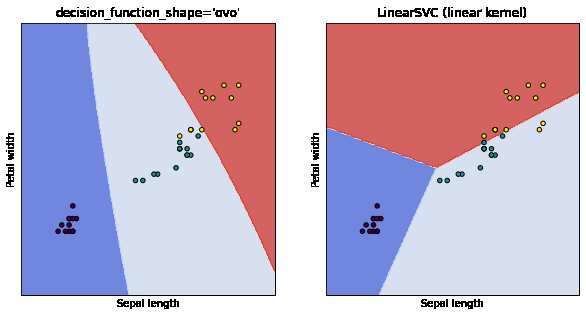
If it isn’t clear, here we have trained 10 different models with each model getting trained on points that the previous model was confused about. Even though I haven’t bothered about the accuracy of the model as the point of the post is to demonstrate the methodology, you can see that the models are able to generalize with a much smaller dataset and that’s exactly the point of active learning. I have still not been able to answer the question of whether active learning yields better models than supervised learning. I guess that’s something I’ll update after further experimentation on a much more complex dataset.
In the next part, I’ll dive deeper into the pipeline design for active learning in computer vision.