One of the best papers I came across in 2020 was the Google Brain team’s Self-training with Noisy Student. It is a semi-supervised technique that works well when we have an insufficient amount of labeled data. So much so that it beat the contemporary SOTA by a whole 2% gain on ImageNet-A top-1% accuracy while increasing the robustness of a classification model at the same time. This paper was arguably the best lockdown read.
Self-training
Self-training is a type of semi-supervised learning. First, let’s clarify what’s the main difference between semi-supervised and supervised learning. In supervised learning, we train the model on the entire dataset (train-test-valid) and the dataset is labeled in its entirety. While on the other hand, in semi-supervised learning, we train a model on the labels of a subset of the dataset. This model is then used to label the remainder of the dataset since the predictions are likely to be better than random. This process is repeated until we get a model that converges.
Generally, semi-supervised datasets are far more ubiquitous since labeling the entire dataset that contains millions of images is a mundane and often an expensive job.
Self-training is a subset of semi-supervised learning and works in the following way:
- Step 1: Split the labeled data instances into train and test sets.
- Step 2: Train a model using this data.
- Step 3a: Use the trained classifier to label (pseudo-labels) the unlabeled instances.
- Step 3b: Weigh the pseudo-labels by model confidence and keep the best ones.
- Step 4: Concatenate the pseudo-labels with the labeled dataset and re-train a new classifier model. (Typically the architecture of the new model isn’t the same as the previous one)
- Step 5: Repeat Step 3 after evaluating classifier performance with a suitable metric. Stop if the model converges.
Self-training can be viewed as a teacher-student technique where once a model is trained on the preliminary dataset, it becomes the teacher that produces pseudo-labels. The student model then learns on the larger dataset containing pseudo-labels.
Noisy Student
The main contribution of the paper from Google Brain is that it adds noise while training the student model. The addition of noise is either done at the input i.e. data augmentation or the model level i.e. dropout and stochastic noise.
Noise, when applied to the unlabeled data, enforces invariances in the decision function of the model. For example, data augmentation forces the student to ensure prediction consistency on the augmented version of images. The teacher labels clean and high-quality images while the student is required to reproduce these labels on a highly augmented version of the original images.
When the noise is applied to the teacher model in the form of dropout and stochastic depth, the teacher model behaves as an ensemble model while producing pseudo-labels. Now the student, a single model, has to master or even outclass an ensemble model.
Two things are important for the noisy student:
- The architecture can be the same for both the teacher and the student but since the student is trained on a much bigger dataset, the model capacity of the student has to be greater than the teacher.
- The student works well on a balanced dataset i.e. the number of pseudo-labels in each class remains roughly the same. In my opinion, this could be idiosyncratic to the ImageNet dataset.

A fair assumption that one can make is that when the pseudo-labels are generated by the same teacher model with respect to the student, the student wouldn’t learn anything new. It might just replicate the knowledge of the teacher without learning anything new. However, since the samples for the students are noisy, it should be much harder for it to generalize as compared to the teacher. The authors also test this idea experimentally and by removing the noise, the performance of the student drops significantly.
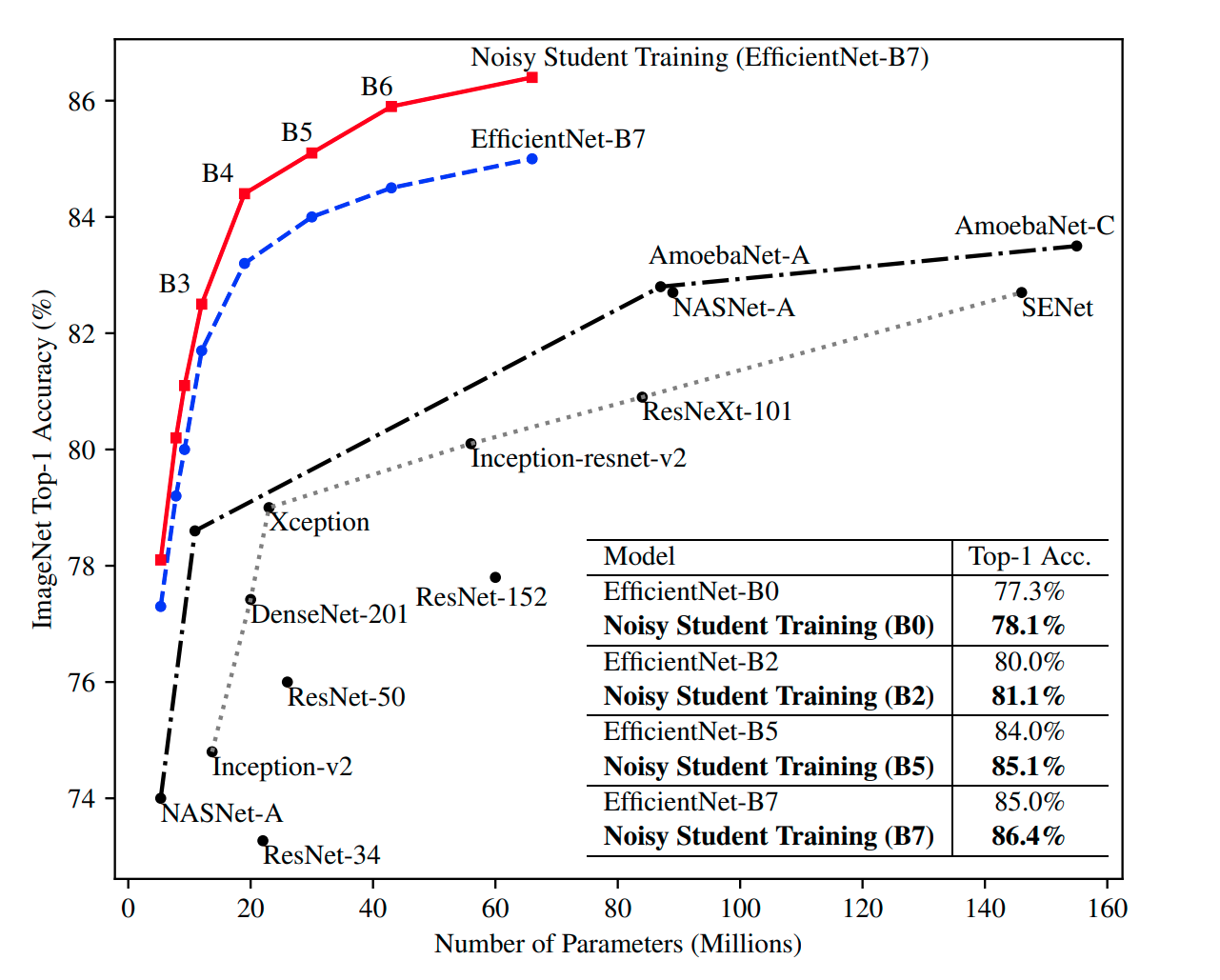
Experimental Details
Architecture
The authors preferred EfficientNets as their baseline models. They also scaled-up EfficientNet-B7 and obtained 3 versions - L0, L1, and L2.
L0 is wider and deeper than B7 while the L1 is scaled up L0 by increasing the width. The authors also utilized the compound scaling technique (from the EfficientNet paper) that uniformly scales width, depth, and input resolution at a fixed rate. Using it, the L2 version was made that is quite large and takes 5x the training time of B7.
Dataset
The dataset used is the famous ImageNet for the labeled images. For the unlabeled images, they used the JFT dataset which has 300M images. EfficientNet B7 was initially trained on ImageNet and was used as a teacher to generate pseudo-labels. A confidence score of 0.3 was used for selecting the best pseudo-labels.
Training
The authors report that after the following iterative training, they obtained the best model. The EfficientNet B7 is improved by using it as both the teacher and the student model. The improved EfficentNet B7 is used as a teacher and a student (EfficientNet L0) is produced. L0 is now used as a teacher while EfficientNet L1(bigger than L0) is used as a student. L1 is now used as a teacher and L2 is used as a student. Now L2 is used as both teacher and a student and there we have it, the best model that beats the state-of-the-art significantly.
Results
The following screenshots are directly from the paper.
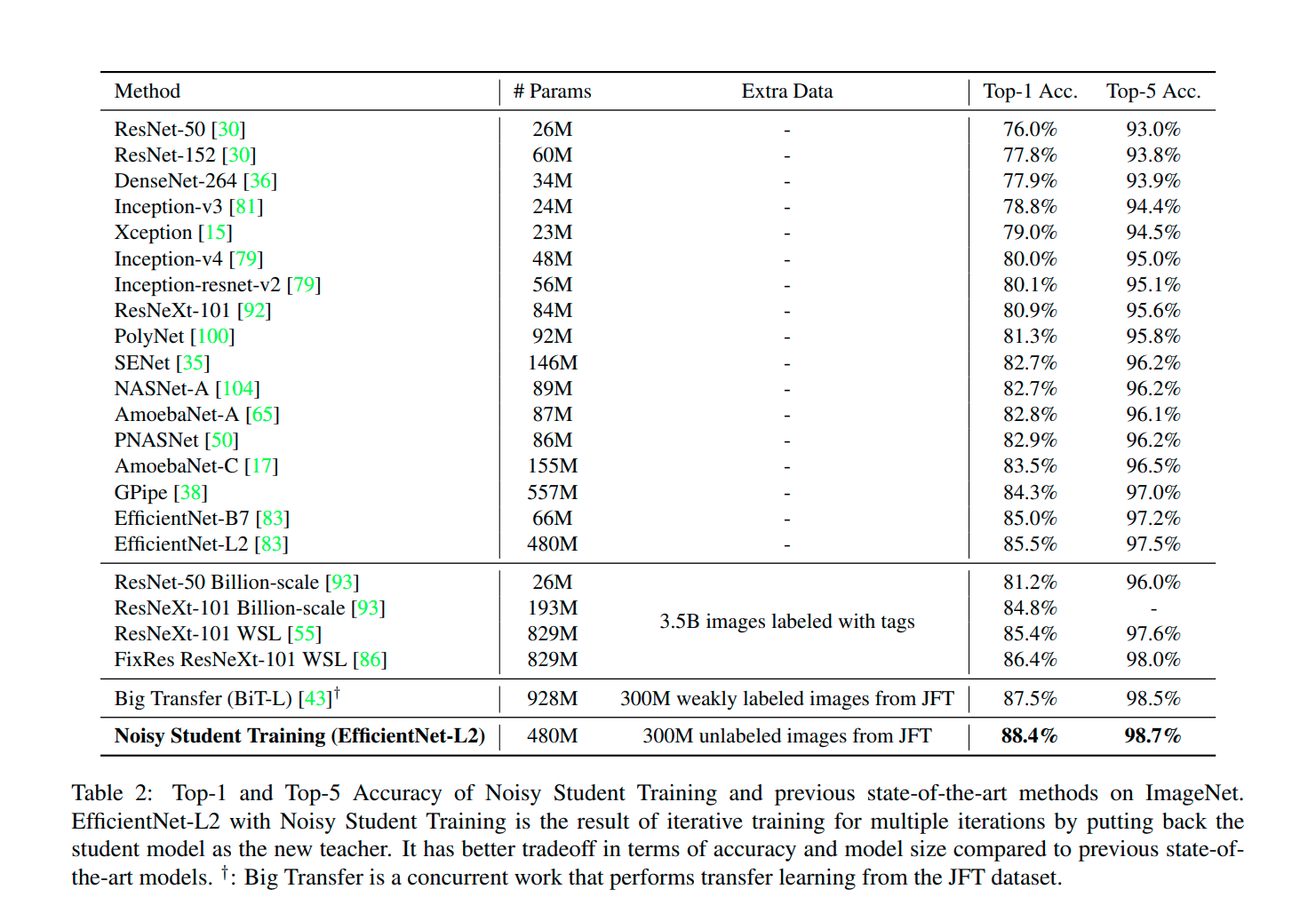
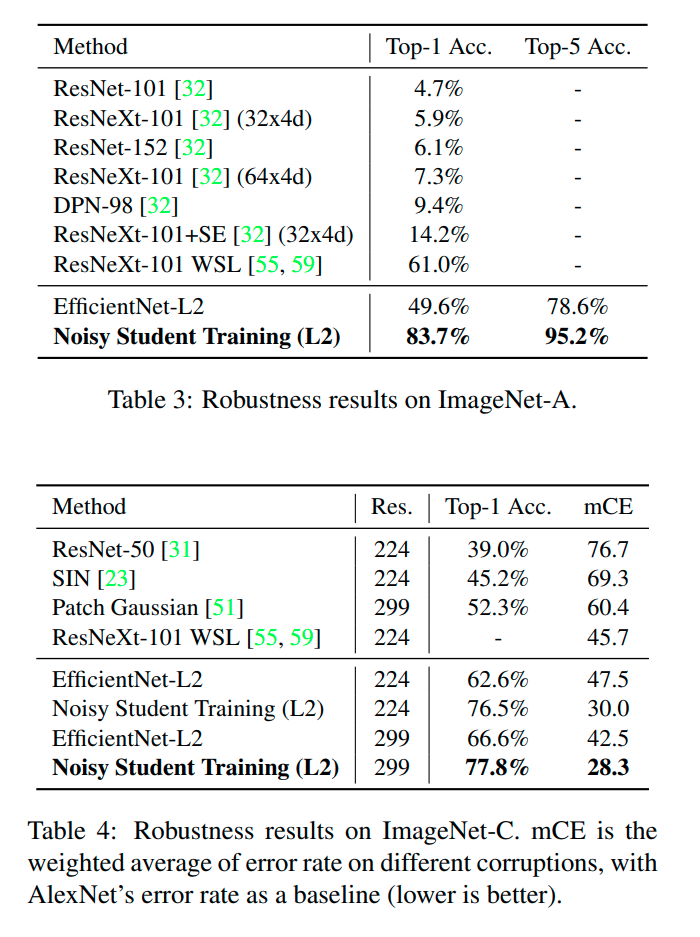
Conclusion
Overall, I like this paper. I have personally believed that semi-supervised learning can and will outperform supervised learning. My experimentation with smaller models and datasets validates the hypothesis and methodology of this paper. Research like this paves a way for high-performance models that don’t require the tedious task of labeling millions of images.
The only point that is a bit concerning in this paper is the use of resources. The idea in itself isn’t new but being a member of Google Brain provides the author a platform for an unparallel execution in terms of the compute required. The author reports that their largest model trained for 3.5 days and needed 2048 core TPU v3 Pod. People still wonder why commercial research labs are highly unprofitable and why only the big tech can afford to perform such research!